NLP
기본 지식
자연어 처리(natural language processing) 기술
2020년 전후로 NLP 분야에서 기술 발전을 이끈 핵심 기술 2가지
- 트랜스포머(Transformer)
- 전이 학습(transformer learning)
이 핵심 기술을 가지고 만들어진 모델 -> BERT와 GPT
정의
NLP 모델 : 자연어를 입력 받아, 해당 입력이 특정 범주일 확률을 반환하는 확률 함수
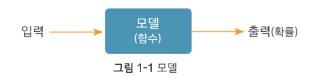 |
 ex) 해당 문장이 긍정, 중립, 부정일 확률 |
모델 종류
입력(자연어)와 목적(감성 분석)에 맞는 최적의 모델을 선정
요즘 인기있는 모델 종류 = 딥러닝(deep learning) : 데이터 패턴을 스스로 익히는 인공지능
딥러닝 기반의 NLP 모델
자연어를 입력 -> 해당 입력이 특정 범주일 확률 출력 -> 후처리를 통해 자연어 형태로 가공해 반환

종류
BERT(Bidirectional Encoder Representations from Transformers)
GPT(Generative Pre-trained Transformers)
사용 목적
- 문서 분류(document classification)
- 문장 쌍 분류(sentence pair classification)
- 개체명 인식(named entity recognition)
- 질의응답(question answering)
- 문장 생성(sentence generation)
딥러닝 모델의 학습
1. 학습 데이터 준비
레이블(label)을 달고 있는 데이터가 필요

2. 학습
학습 데이터를 기반으로 모델이 패턴(pattern)을 스스로 익힘
학습 : 출력이 정답에 가까워지도록 모델을 업데이트 하는 과정
 |
 |
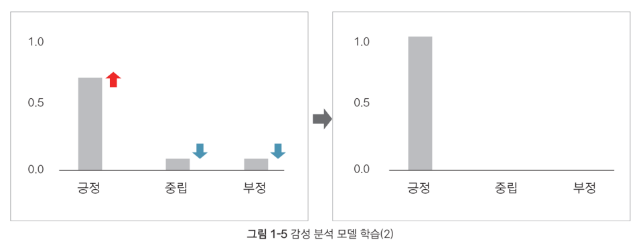 |
트랜스퍼 러닝(transfer learning)
정의
특정 태스크를 학습한 모델을 다른 태스크 수행에 재사용하는 기법

장점
- 기존보다 모델의 학습 속도 향상
- 기존에는 처음부터 태스크에 대한 학습 진행 = 사전 지식 없이 새로운 지식 배움
- 새로운 태스크 더 잘 수행
용어
- 업스트림(upstream) : 대규모 말뭉치의 문맥을 이해하는 과정
- 다운스트림(downstream) : 우리가 해결하고자 하는 자연어 처리의 문제
- 사전학습(pretrain) : 업스트림 태스크를 학습하는 과정
업스트림 태스크
트랜스퍼 러닝이 주목을 받게된 주인공
자연어의 풍부한 문맥을 모델에 사전 학습 진행 -> 사전 학습된 모델을 다양한 다운스트림 태스크에 적용
종류
아래 2종류는 모두 자기지도 학습(self-supervised learning)으로 진행
- 지도 학습(supervised learning) : 사람이 일일이 정답(레이블)을 만들고 이를 바탕으로 학습
=> 비용(시간) 많이 듬 + 실수가 발생할 수 있음
- 자기지도 학습(self-supervised learning) : 데이터 내에서 정답을 만들고 이를 바탕으로 학습하는 방법
- 다음 단어 맞히기 : 이전 문맥을 고려했을 때, 어떤 단어가 그다음에 오는 것이 자연스로운지 학습

- 언어 모델(Language Model) : 다음 단어 맞히기로 업스트림 태스크를 수행한 모델
- 언어 모델 학습 방법
- 분류해야할 범주(출력 종류)가 학습 대상의 언어의 어휘 수( 수만개 이상 )만큼 존재
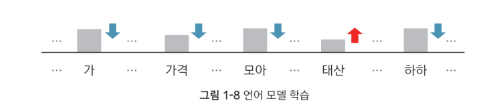
- 빈칸 채우기 : 문장에서 빈칸을 만들고, 앞뒤 문맥을 보고 적합한 단어를 찾는 과정을 학습

- 마스크 언어 모델(masked language model) : 빈칸 채우리로 업스트림 태스크를 수행한 모델
ex) BERT 모델
다운스트림 태스크
정의
- 우리가 실제로 풀어야 할 자연어 처리의 과제
- 해당 과제를 풀기 위해 업스트림 태스크를 통해 사전학습을 마친 모델을 사용
- 주로, 분류(classification)를 하는데 사용 - 자연어를 입력받아 특정 범주에 속할 확률 형태로 반환
종류
- 파인튜닝(fine-tuning) : 사전 학습을 마친 모델을 다운스트림 태스크에 맞게 업데이트하는 기법
문서 분류 : 자연어를 입력받아, 해당 입력이 어떤 범주에 속하는지 확률 값을 반환
사전 학습을 마친 모델(노란색 실선 박스) 위에 작은 모듈(초록색 실선 박스)를 하나 더 쌓아 문서 전체의 범주를 분류

자연어 추론 : 문장 2개를 입력받아, 두 문장 사이의 관계가 어떤 범주인지 확률 값을 반환
참(entailment), 거짓(contradiction), 중립(neutral)이 존재

개체명 인식 : 자연어를 입력받아, 단어별로 어떤 개체명 범주에 속하는지 확률 값을 반환
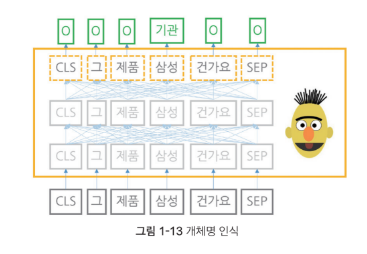
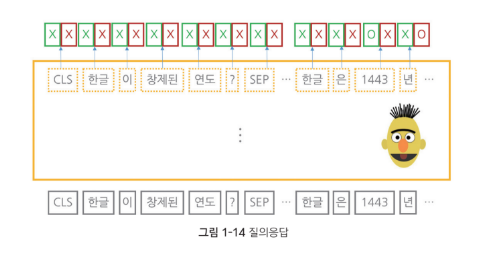
질의 응답 : 질문 + 답변을 입력받아, 각 단어가 정답의 시작일 확률값과 끝일 확률값을 반환
문장 생성 : 자연어를 입력받아, 어휘 전체에 대한 확률값을 반환 -> 해당 확률을 통해 다음에 올 단어로 적합한 단어 선택
GPT 계열 언어 모델이 널리 쓰는 방법

'CS > NLP' 카테고리의 다른 글
| 이론 2-3. 실습 - 어휘 집합 구축 (0) | 2023.11.10 |
|---|---|
| 이론 2-3. 워드피스(wordpiece) (0) | 2023.11.10 |
| 이론 2-2. 바이트 페이 인코딩(BPE) (0) | 2023.11.10 |
| 이론 2-1. 토큰화 (0) | 2023.11.10 |
| 이론 모델 학습 파이프라인 (0) | 2023.10.19 |