MSA
개요
- 하나의 대규모 모놀리식 애플리케이션보다 여러 개의 작은 애플리케이션으로 시스템을 구축하는 방식
- 각 마이크로서비스는 특정 작업을 담당하며, 다른 것에 의존하지 않고 독립적으로 배포되도록 설계된 매우 작은 응용 프로그램
특징
- 작고 느슨하게 결합된 애플리케이션 -> 필요한 경우 수평으로 쉽게 확장 가능
- 예를 들어 필요한 경우 동일한 MSA 인스턴스를 10개 더 시작 할 수 있어야함 -> 이거는 모두 그룹으로 작동
- 스프링 프레임워크는 MSA 구축을 위한 다양한 기능을 제공
vs 모놀로식

| 모놀로식 | MSA | |
| 변경사항 발생 | 전체 시스템의 재빌드 요구 | 변경된 서비스만 독립적으로 배포 |
| DB구조 | 하나의 DB에 모든 데이터 저장 (사용자, 상품, 주문...) |
각 서비스마다 별도의 DB를 사용 -> 서비스간 DB 접근이 불가 -> 서비스간 통신 필요 |
MSA간 통신
HTTP 요청/응답 방식

- MSA 서비스간 HTTP 요청/응답 방식으로 소통 가능
- 그러나 HTTP 방식은 한 서비스에서 여러 서비스에 동시에 메시지를 전달해야할 때 몇가지 문제가 존재
- 새로운 서비스가 생길 때마다 기존 서비스에 새로운 통신 로직을 추가
- 서비스 중 하나에 문제가 생긴다면, 계속 그 부분에서 불필요한 패킷 손실 발생하고, 해당 이벤트를 다시 볼 수 없음
- 즉, HTTP 방식은 여러 MSA에게 메세지를 동시에 전달해야할때 너무 비효율적 -> 이벤트 기반 아키텍처로 가자!
이벤트 중심 통신 방식
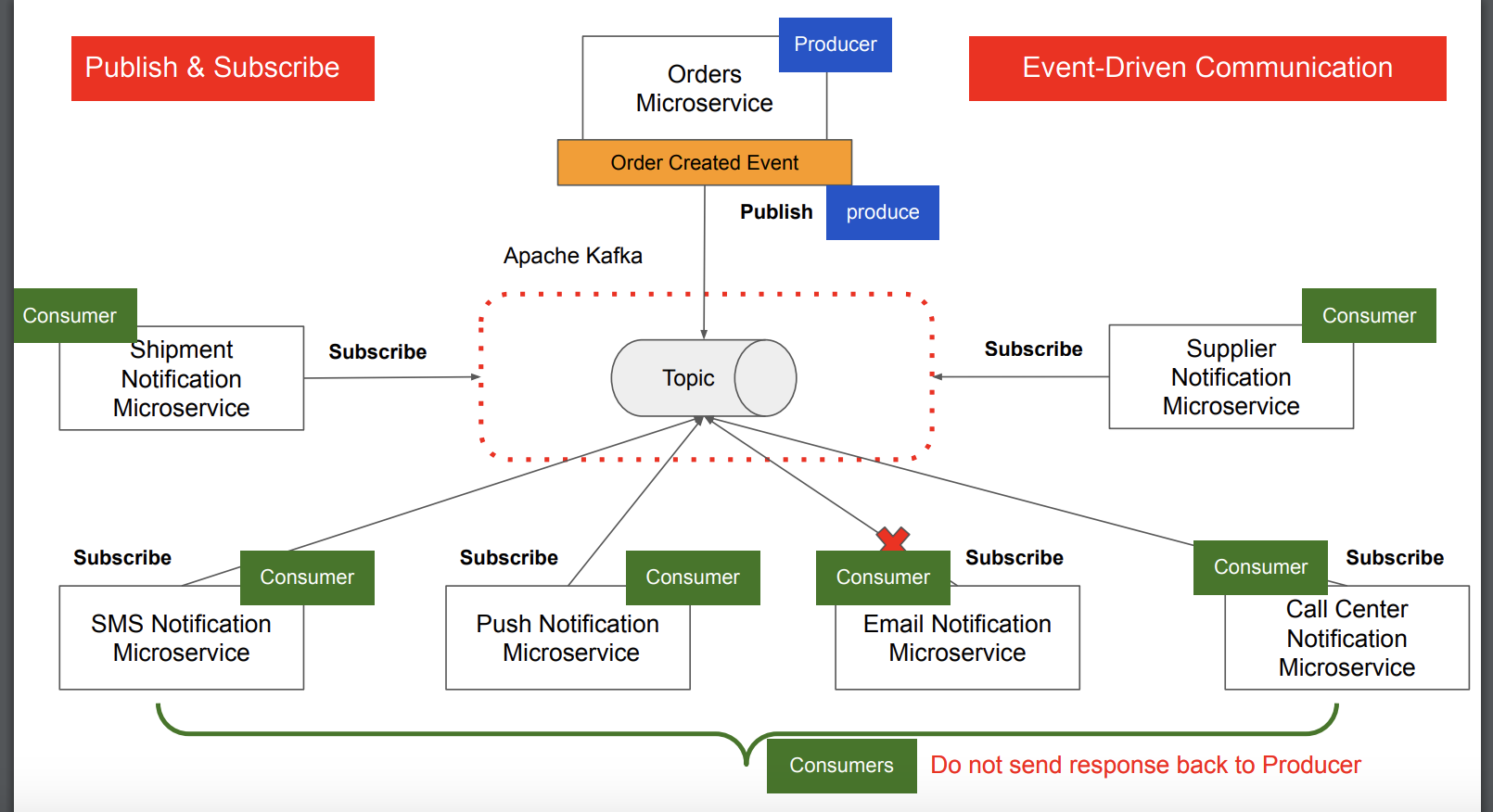
- 이벤트를 생성하는 서비스(게시자, Producer)와 이벤트를 처리하는 서비스(구독자, Consumer)간의 느슨한 결합을 통해 발생
- 게시자는 특정 이벤트가 발생했음을 알리기 위해 이를 중앙의 이벤트 저장소(토픽 등)에 게시(publish)하며,
- 구독자는 해당 이벤트를 저장소에서 구독(subscribe)하여 가져와 처리하는 방식
특징
- 게시자는 구독자가 몇명이고, 몇 명이 이벤트를 성공적으로 처리했는지 알 수 없음
- 구독자는 게시자에게 직접 응답을 다시 보내지 않음
- 구독자 중 하나가 다운되도, 다시 복구후 해당 이벤트를 받아와 처리 가능 -> 엄청난 장점!
Apache Kafka를 사용하면 MSA 간의 통신을 이벤트 중심으로 전환 가능!
Apache Kafka
- 대규모 데이터 수집, 처리, 저장 및 통합을 위한 분산 이벤트 스트리밍 플랫폼

주요 구성 요소
- 생산자(Producer): 이벤트를 생성하여 브로커에게 전달
- 브로커(Broker): 생산자로부터 게시된 이벤트를 수락하고 저장하는 서버로, 하드 디스크에 데이터를 저장
- 고가용성을 위해 여러 개의 브로커와 파티션 복제를 사용
- 토픽(Topic): 브로커 내에서 이벤트가 저장되는 공간
- 여러 파티션으로 나뉘어 짐
- 파티션은 이벤트를 병렬로 처리할 수 있도록 분할된 저장 공간
- 각 파티션 내의 셀에 이벤트가 순차적으로 저장
- 소비자(Consumer): 토픽에서 이벤트를 읽어 처리
- 이벤트는 소비된 후에도 일정 기간 동안 토픽에 남아 있어 다른 소비자들도 해당 이벤트를 읽을 수 있음 ( 기본 7일 )
더보기
질문:
카프카를 쓰면 MSA 인스턴스를 자유롭게 오토 스케일링 할 수 있다?
- 여기서 소비자에 대한 오토 스케일링이 자유로움
메세지(Message)와 이벤트(Event)

이벤트
- 이벤트는 시스템에서 발생한 중요한 동작이나 상태 변화를 나타내는 것
- 즉, 시스템내에서 무언가가 발생했다는 것을 나타내는 것
- 이벤트의 명명 규칙:
- <명사><과거형>Event
- 예: ProductCreatedEvent (상품 생성됨)
- 이벤트 값은 String, Json 등 페이로드 정보를 담고있는 Bytes 정보
메시지
- 이벤트를 포함하는 컨테이너
- 구성 요소:
- 키(Key): 이벤트를 특정 파티션에 매핑하는 데 사용
- 값(Value): 이벤트의 실제 데이터(페이로드)
- 키와 값은 JSON, String, Null 등의 형태를 가짐
- 타임스탬프(Timestamp): 이벤트가 생성된 시간
- 헤더(Headers): 추가 메타데이터(선택 사항)
- 메시지의 페이로드는 직렬화되어 저장되며, 소비자는 이를 역직렬화하여 사용
- +) 이벤트 객체는 이벤트에 대한 모든 정보를 포함해야하지만, 규모가 커진다면 최적화를 고민해야함 ( ex: 이미지, 동영상 )
토픽(Topic)과 파티션(Partition)

토픽
- 특정 유형의 이벤트를 구분하기 위한 이름 공간
- 각 토픽은 여러 개의 파티션으로 구성
- 파티션을 사용하면 이벤트를 병렬로 처리할 수 있어 시스템의 확장성이 향상
- 동일한 토픽 내의 파티션 수를 늘리면 소비자를 수평으로 확장 가능
더보기
질문:
- Topic을 여러개 파티션으로 구성하면, 구독자 MSA를 수평으로 확장할 수 있다고? 이게 뭔 개소리
- 서로 다른 파티션마다 서로 다른 양의 이벤트가 저장될 수 있다?? -> 이게 뭔 개소리
- Events are in order within a partition. Order across partitions is not maintained,??
파티션
- 파티션에는 여러개의 셀이 존재하고, 각 셀에 번호 존재 → Offset
- 파티션은 추가 전용으로, 이벤트가 저장되면 변경이나 삭제가 불가하며 항상 끝에 추가
- 새로운 이벤트 들어오면 Offset 증가하며 저장( 예: 첫 번째 이벤트는 offset 0, 이후는 1 )
- 파티션 내에서는 순서 유지, 파티션 간 순서 보장 안 됨
- 이벤트는 소비 후에도 7일간 유지 (기본값)
Events Ordering(이벤트 순서)
문제점
- 메시지 키가 제공되지 않으면 이벤트는 임의의 파티션에 저장
- 메시지 키가 제공되지 않으면, 카프카가 이벤트를 로드 밸런싱해서 하나의 파티션에 넣으려고 함
- 이로 인해 이벤트 처리 순서가 보장되지 않음
- 소비자들은 여러 파티션에서 이벤트를 병렬로 읽기 때문에 순서가 중요한 경우 문제가 발생

- 사용자 A가 프로필을 A → B → C로 변경하여 3개의 이벤트가 발생했다고 가정
- 메시지 키를 사용하지 않으면 이 이벤트들은 서로 다른 파티션에 저장될 수 있으며, 소비자가 이벤트를 처리하는 순서가 보장되지 않음
해결방안
- 따라서 이렇게 순서대로 이벤트가 처리되아야 하는 상황에서는 메시지 키를 제공해라!
- 메시지 키가 제공되면 해당 이벤트가 어느 파티션에 저장될지 결정할 수 있다.
- 동일한 메시지 키를 사용하면 이벤트는 동일한 파티션에 저장되어, 해당 파티션 내에서 순서가 유지
- 카프카는 생산자(producer)에 의해 도착한 순서대로 이벤트를 읽도록 순서를 보장

- 메시지 키로 사용자 ID(User ID)를 사용하여 이벤트들이 동일한 파티션에 저장되어 순서가 유지
더보기
- 힝 그러면 파티션이 가득차서 생기는 문제는 어떻게 처리하지?!
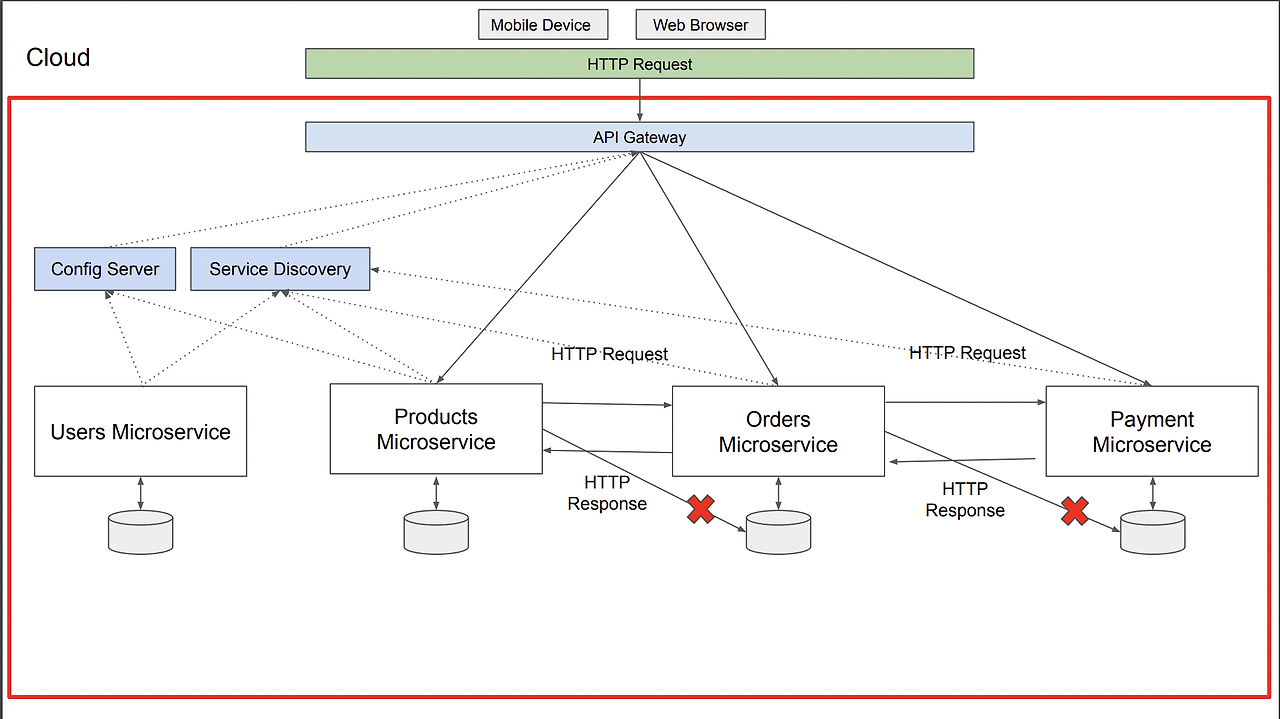
- 아래 MSA는 고유한 포트번호에서 실행되는 작은 웹 서비스
- 빨간색 상자는 MSA를 지원하는 Spring Cloud기 존재
- API Gateway는 독립형 스프링 부트 애플리케이션이기도 함
- 구성 서버(config server)와 서비스 검색(Service Discovery) 모두 스프링 애플리케이션
- 서로간의 정보에 접근을 해야한다면, 바로 DB에 접근하는것은 허용하지 않으며, 서로간의 HTTP 요청/응답을 통해 주고 받음
- 즉, HTTP는 MSA의 소통 수단 중 하나 -> 이때, 동기/비동기 HTTP 방식 둘다 목적에 따라서 잘 활용됨
'Kafka' 카테고리의 다른 글
| 2. Kafka를 위한 도커 컴포즈 파일 설정 (0) | 2024.10.23 |
|---|